Usage
Currently, typed pojo DTOs are supported, thus you will need to add the generator to the project where you would like to generate your documents.
For a showcase suppose the HR at your company uses the following document to summarize basic employee data:
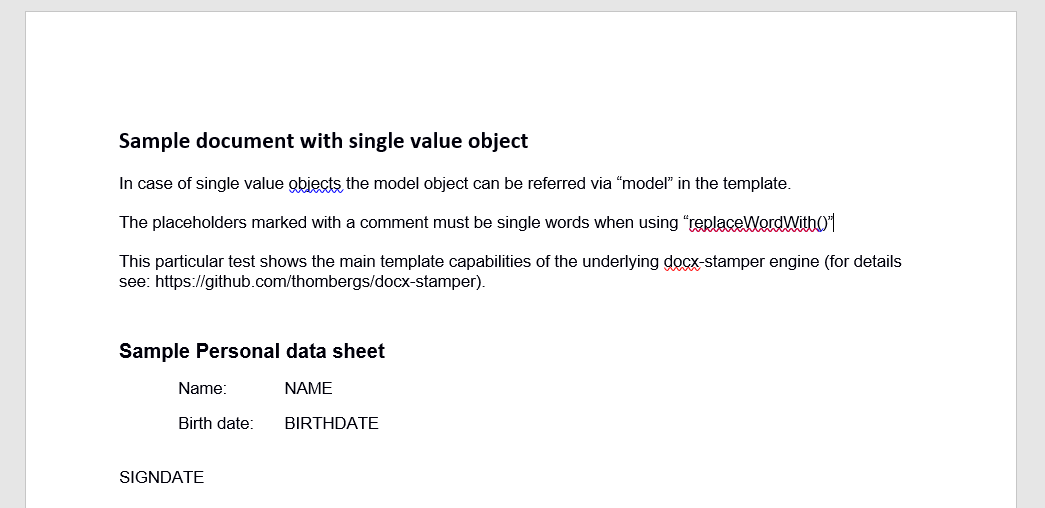 (download: personal_data_sheet_v1_3.docx)
(download: personal_data_sheet_v1_3.docx)
How it works
(In this example we assume a java project)
- Construct the DTO you will use within the templates
As we can see in the form (and spec., etc. of course) we got, we have the provide the properties below (in most cases we will have these classes in our business logic already done):
package net.videki.documentengine.test.dto.contract;
import lombok.AllArgsConstructor;
import lombok.Data;
import dto.net.videki.documentengine.core.ITemplate;
import java.time.LocalDate;
@Data
@AllArgsConstructor
public class Person implements ITemplate {
private String name;
private LocalDate birthDate;
private LocalDate signDate;
}
Implementing the ITemplate interface is optional, it provides convenience functions
you can use in your templates.
- Markup the template
Now, add the control to the template:
 (download: personal_data_sheet_v1_3-template.docx)
(download: personal_data_sheet_v1_3-template.docx)
- Add maven dependency
Maven:
<dependency>
<groupId>net.videki.getthedocs</groupId>
<artifactId>docs-core</artifactId>
<version>1.0.1</version>
</dependency>
Gradle:
compile group: 'net.videki.getthedocs', name: 'docs-core', version: '1.0.1'
- Add the generator config (document-engine.properties) to the project resources
# Document structure repository provider
repository.documentstructure.provider=filesystem.repository.documentstructure.provider.net.videki.documentengine.core.FileSystemDocumentStructureRepository
repository.documentstructure.builder=yaml.builder.documentstructure.provider.net.videki.documentengine.core.YmlDocStructureBuilder
repository.documentstructure.provider.basedir=documentstructures
# Template repository provider class
repository.template.provider=filesystem.templaterepository.provider.net.videki.documentengine.core.FileSystemTemplateRepository
repository.template.provider.basedir=templates
# InputTemplate processors
processors.docx=docx.input.processor.net.videki.documentengine.core.DocxStamperInputTemplateProcessor
processors.xlsx=xlsx.input.processor.net.videki.documentengine.core.JxlsInputTemplateProcessor
# Result repository provider class
repository.result.provider=filesystem.resultstore.provider.net.videki.documentengine.core.FileSystemResultStore
repository.result.provider.basedir=generated-documents
# Font base directory
converter.pdf.font-library.basedir=/fonts
(download: document-engine.properties)
- The
repository.documentstructure.provider.basedirproperty specifies the template root location. This can be also set to an external location containing the templates.
There is a helper class to handle folders within this doc root and provide full path for the template as shown in the code below (seeFileSystemHelper.getFileNameWithPath(inputDir, fileName)). - The
repository.result.provider.basedirproperty specifies the result root location. By default the basedir root is the output dir with the template name. This can be overridden by specifying the generation behaviour withDocumentStructure.
- Add the document generator functionality to the business logic
The sample code below shows a simple fill-and-save scenario to the output dir, but the result can also be requested
as a stream. See the TemplateService interface for more information.
package net.videki.documentengine.examples;
import net.videki.documentengine.examples.singletemplatepojo.dto.Person;
import service.net.videki.documentengine.core.TemplateServiceRegistry;
import exception.service.net.videki.documentengine.core.TemplateServiceException;
import util.net.videki.documentengine.core.FileSystemHelper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.LocalDate;
import java.time.Month;
public class SingleTemplateDocxPojo {
private static final Logger LOGGER = LoggerFactory.getLogger(SingleTemplateDocxPojo.class);
// Only to demonstrate the usage
public static void main(String[] args) {
final SingleTemplateDocxPojo appService = new SingleTemplateDocxPojo();
appService.generateDocs();
}
public void generateDocs() {
final String inputDir = "hr-files";
final String fileName = "personal_data_sheet_v1_3-template.docx";
final var data = getTemplateData();
try {
TemplateServiceRegistry.getInstance().fillAndSave(
FileSystemHelper.getFileNameWithPath(inputDir, fileName),
data);
} catch (final TemplateServiceException e) {
LOGGER.error("Error generating the result doc.", e);
}
}
private Person getTemplateData() {
// Mocking the business logic
return new Person("John Doe",
LocalDate.of(1970, Month.JULY, 20),
LocalDate.of(2020, Month.NOVEMBER, 1));
}
}
Done.
Dealing with multiple documents in a workflow
In many cases more than one document has to be generated in a workflow. To support this, we introduced document structures to be handled by the engine. The idea is to collect data during the workflow and generate the required documents based on the actual data in a single step at the end of the process (this also ensures that at the end of the process only the required set of documents will be generated with up to date content, instead of re-generating and filtering previously processed results).
Showcase
Suppose we are writing a software for a phone provider company, and our task is to generate contract documents for new clients. Due legal purposes the contracts have to be signed by the clients personally at the company's seller offices. These offices have multiple teller desks sharing one multifunctional printer per office.
The contract consists of the following parts:
- the customer contract itself (contains client and officer data)
- conditions and fees (contains client data)
- terms of use (static text)
The contract depends on the client's nationality. If a contract with the client's language is available, that one shall be used, english otherwise. All other documents have to be generated in the given format. The document headers should contain the office, and the officer reference with each page having a QR code with a link pointing to the client's profile in company's CRM. To separate the handouts a cover page has to be printed for all contract with the officer's name, and the generation time.
So, in our case the documents for an officer should look like below:
Cover page

Contract

Terms

In our case the following document structure can be used:
(note: the ids given are generated uuid-s, but you can use any according to the actual needs)
# contract_v02.yml
---
documentStructureId: "109a562d-8290-407d-98e1-e5e31c9808b7"
elements:
- templateElementId:
id: "cover"
templateNames:
hu_HU: "/covers/cover_v03.docx"
defaultLocale: "hu_HU"
count: 1
- templateElementId:
id: "contract"
templateNames:
en: "/contracts/vintage/contract_v09_en.docx"
hu: "/contracts/vintage/contract_v09_hu.docx"
defaultLocale: "hu_HU"
count: 1
- templateElementId:
id: "terms"
templateNames:
hu: "/term/terms_v02.docx"
defaultLocale: "hu_HU"
count: 1
- templateElementId:
id: "conditions"
templateNames:
hu: "/conditions/vintage/conditions_eco_v11.xlsx"
defaultLocale: "hu_HU"
count: 1
resultMode: "SEPARATE_DOCUMENTS"
outputFormat: "UNCHANGED"
copies: 1
Generating the actual result can be done like below:
try {
final DocumentStructure structure = getContractDocStructure();
final var tranId = UUID.randomUUID().toString();
final ValueSet values = new ValueSet(structure.getDocumentStructureId(), tranId);
values.getValues().put(TemplateElementId.getGlobalTemplateElementId(), getContractTestData(tranId));
result = ts.fillAndSave(structure, values);
} catch (final TemplateNotFoundException | TemplateServiceException e) {
testResult = false;
}
Well, that's it.